









PDF 파일의 스프레드시트에서 Microsoft Excel 시트로 데이터를 전송하는 작업은 항상 "재미" 있습니다. 특히 FineReader 또는 이와 유사한 것과 같은 값비싼 인식 소프트웨어가 없는 경우. 직접 복사는 일반적으로 좋은 결과로 이어지지 않습니다. 복사한 데이터를 시트에 붙여넣은 후 하나의 열에 "함께 붙어" 있을 가능성이 큽니다. 따라서 도구를 사용하여 힘들게 분리해야 합니다. 열별 텍스트 탭에서 Data (데이터 — 텍스트를 열로).
물론 복사는 텍스트 레이어가 있는 PDF 파일에 대해서만 가능합니다. 즉, 종이에서 PDF로 방금 스캔한 문서의 경우에는 원칙적으로 작동하지 않습니다.
하지만 그렇게 슬프지 않아요, 정말 🙂
Office 2013 또는 2016이 있는 경우 추가 프로그램 없이 몇 분 안에 PDF에서 Microsoft Excel로 데이터를 전송할 수 있습니다. 그리고 Word와 Power Query는 이것에 도움이 될 것입니다.
예를 들어, 유럽 경제 위원회(Economic Commission for Europe) 웹사이트에서 가져온 많은 텍스트, 공식 및 표가 포함된 이 PDF 보고서를 살펴보겠습니다.

... 그리고 Excel에서 꺼내려고 시도합니다. 첫 번째 표를 말합니다.

가자!
1단계. Word에서 PDF 열기
어떤 이유에서인지 아는 사람은 거의 없지만 2013년부터 Microsoft Word는 PDF 파일(텍스트 레이어 없이 스캔한 파일도 포함)을 열고 인식하는 방법을 배웠습니다. 이것은 완전히 표준적인 방식으로 수행됩니다. Word를 열고 파일 – 열기 (파일 — 열기) 창의 오른쪽 하단 모서리에 있는 드롭다운 목록에서 PDF 형식을 지정합니다.
그런 다음 필요한 PDF 파일을 선택하고 엽니다 (열다). Word에서는 이 문서에서 OCR을 텍스트로 실행할 것이라고 알려줍니다.

우리는 동의하고 몇 초 안에 PDF가 이미 Word에서 편집용으로 열려 있는 것을 볼 수 있습니다.

물론 디자인, 스타일, 글꼴, 머리글 및 바닥글 등은 문서에서 부분적으로 날아갈 것이지만 이것은 우리에게 중요하지 않습니다. 우리는 테이블의 데이터만 필요합니다. 원칙적으로 이 단계에서는 이미 인식된 문서의 표를 Word로 복사하고 Excel에 붙여넣기만 하면 됩니다. 때로는 작동하지만 더 자주 모든 종류의 데이터 왜곡으로 이어집니다. 예를 들어 숫자가 날짜로 바뀌거나 우리의 경우와 같이 텍스트로 남을 수 있기 때문입니다. PDF는 비 구분 기호를 사용합니다.

그러니 모퉁이를 자르지 말고 모든 것을 조금 더 복잡하게 만들지 만 옳습니다.
2단계: 문서를 웹 페이지로 저장
그런 다음 수신된 데이터를 파워 쿼리를 통해 Excel로 로드하려면 Word의 문서를 웹 페이지 형식으로 저장해야 합니다. 이 형식은 이 경우 Word와 Excel 간의 일종의 공통 분모입니다.
이렇게하려면 메뉴로 이동하십시오. 파일 – 다른 이름으로 저장 (파일 — 다른 이름으로 저장) 또는 키를 누르십시오 F12 키보드와 열리는 창에서 파일 형식을 선택하십시오. 하나의 파일로 된 웹페이지 (웹페이지 — 단일 파일):

저장 후 확장자가 mhtml인 파일을 가져와야 합니다(탐색기에 파일 확장자가 표시되는 경우).
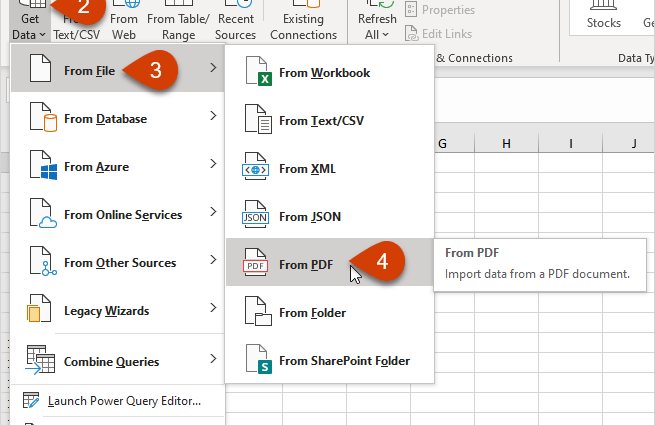
3단계. 파워 쿼리를 통해 Excel에 파일 업로드
생성된 MHTML 파일을 Excel에서 직접 열 수 있지만 먼저 PDF의 모든 내용과 텍스트 및 불필요한 테이블을 한 번에 가져오고 두 번째로 잘못된 데이터로 인해 데이터가 다시 손실됩니다. 구분자. 따라서 Power Query 추가 기능을 통해 Excel로 가져오기를 수행합니다. 이것은 거의 모든 소스(파일, 폴더, 데이터베이스, ERP 시스템)에서 Excel로 데이터를 업로드한 다음 수신된 데이터를 가능한 모든 방식으로 변환하여 원하는 모양을 제공할 수 있는 완전 무료 추가 기능입니다.
Excel 2010-2013이 있는 경우 공식 Microsoft 웹 사이트에서 Power Query를 다운로드할 수 있습니다. 설치 후 탭이 표시됩니다. 파워 쿼리. Excel 2016 이상이 있는 경우 아무 것도 다운로드할 필요가 없습니다. 모든 기능은 기본적으로 Excel에 이미 내장되어 있으며 탭에 있습니다. Data (데이트) 그룹에서 다운로드 및 변환 (가져오기 및 변환).
그래서 우리는 탭으로 이동합니다. Data, 또는 탭에서 파워 쿼리 그리고 팀을 선택 데이터를 얻으려면 or 쿼리 생성 – 파일에서 – XML에서. XML 파일뿐만 아니라 표시하려면 창의 오른쪽 하단 모서리에 있는 드롭다운 목록에서 필터를 다음으로 변경합니다. 모든 파일 (모든 파일) MHTML 파일을 지정합니다.

가져오기가 성공적으로 완료되지 않습니다. 파워 쿼리는 XML을 기대하지만 실제로는 HTML 형식이 있습니다. 따라서 나타나는 다음 창에서 파워 쿼리가 이해할 수 없는 파일을 마우스 오른쪽 버튼으로 클릭하고 형식을 지정해야 합니다.

그런 다음 파일이 올바르게 인식되고 포함된 모든 테이블 목록이 표시됩니다.

데이터 열에 있는 셀의 흰색 배경(단어 테이블이 아님)에서 마우스 왼쪽 버튼을 클릭하여 테이블의 내용을 볼 수 있습니다.
원하는 테이블이 정의되면 녹색 단어를 클릭하십시오. 작업대 – 그리고 당신은 그 내용으로 "떨어집니다":

내용을 "빗질"하려면 다음과 같은 몇 가지 간단한 단계를 수행해야 합니다.
- 불필요한 열 삭제(열 머리글을 마우스 오른쪽 버튼으로 클릭 - 제거)
- 점을 쉼표로 교체(열 선택, 마우스 오른쪽 버튼 클릭 – 값 바꾸기)
- 헤더에서 등호 제거(열 선택, 마우스 오른쪽 버튼 클릭 – 값 바꾸기)
- 맨 윗줄 제거(홈 – 라인 삭제 – 맨 위 라인 삭제)
- 빈 줄 제거 (홈 – 줄 삭제 – 빈 줄 삭제)
- 첫 번째 행을 테이블 헤더(홈 – 첫 번째 줄을 제목으로 사용)
- 필터를 사용하여 불필요한 데이터 필터링
테이블이 정상적인 형태로 바뀌면 다음 명령을 사용하여 시트에 언로드할 수 있습니다. 닫고 다운로드 (닫기 및 로드) on 주요 탭. 그리고 우리는 이미 일할 수있는 아름다움을 얻을 것입니다.

- 파워 쿼리를 사용하여 열을 테이블로 변환
- 고정 텍스트를 열로 분할