









내용
현재 Microsoft Excel에는 함수 마법사 창을 통해 사용할 수 있는 거의 XNUMX개의 워크시트 함수가 있습니다. fx 수식 입력줄에서 이것은 매우 괜찮은 세트이지만, 그럼에도 불구하고 조만간 거의 모든 사용자가 이 목록에 자신이 필요로 하는 기능이 포함되어 있지 않은 상황에 직면하게 됩니다. 단순히 Excel에 없기 때문입니다.
지금까지 이 문제를 해결하는 유일한 방법은 매크로였습니다. 즉, Visual Basic에서 사용자 정의 함수(UDF = User Defined Function)를 직접 작성하는 것이었습니다. 이는 적절한 프로그래밍 기술이 필요하고 때로는 전혀 쉽지 않습니다. 그러나 최신 Office 365 업데이트로 상황이 개선되었습니다. Excel에 특별한 "래퍼" 기능이 추가되었습니다. 람다. 그것의 도움으로 자신의 기능을 만드는 작업이 이제 쉽고 아름답게 해결됩니다.
다음 예제에서 사용 원리를 살펴보겠습니다.
아시다시피 Excel에는 주어진 날짜의 일, 월, 주 및 연도 수를 결정할 수 있는 여러 날짜 구문 분석 기능이 있습니다. 그런데 어째서인지 분기의 수를 결정하는 기능은 없고, 이것도 종종 필요하겠죠? 이 단점을 수정하고 람다 이 문제를 해결하기 위해 자신의 새로운 기능.
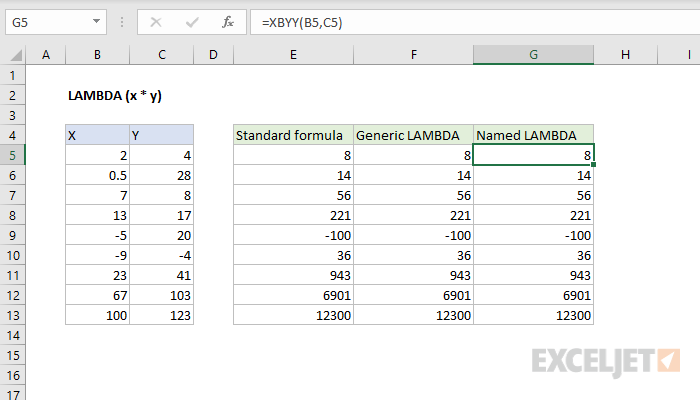
1단계. 수식 작성
일반적인 방법으로 수동으로 필요한 것을 계산하는 수식을 시트 셀에 작성한다는 사실부터 시작하겠습니다. 분기 번호의 경우 예를 들어 다음과 같이 수행할 수 있습니다.

2단계. LAMBDA에서 마무리 및 테스트
이제 새로운 LAMBDA 함수를 적용하고 수식을 래핑할 시간입니다. 함수 구문은 다음과 같습니다.
=람다(변수1; 변수2; … 변수N ; 표현)
여기서 하나 이상의 변수 이름이 먼저 나열되고 마지막 인수는 항상 이를 사용하는 공식 또는 계산된 표현식입니다. 변수 이름은 셀 주소처럼 보이지 않아야 하며 점이 포함되어서는 안 됩니다.
우리의 경우에는 분기 번호를 계산하는 날짜라는 하나의 변수만 있을 것입니다. 변수를 d라고 합시다. 그런 다음 수식을 함수로 래핑합니다. 람다 원본 셀 A2의 주소를 가상의 변수 이름으로 대체하면 다음을 얻습니다.

이러한 변환 후에는 A2 셀의 원래 날짜가 이전되지 않았기 때문에 수식(실제로 정확합니다!)에서 오류가 발생하기 시작했습니다. 테스트와 확신을 위해 함수 뒤에 인수를 추가하여 인수를 전달할 수 있습니다. 람다 괄호 안:

3단계. 이름 만들기
이제 쉽고 재미있는 부분을 위해. 우리는 엽니 다 이름 관리자 탭 공식 (수식 — 이름 관리자) 버튼으로 새 이름을 만듭니다. 만들기 (창조하다). 미래 기능의 이름을 생각해내고 입력하십시오(예: 놈크바르탈라), 그리고 현장에서 (링크) (참고) 수식 입력줄에서 조심스럽게 복사하여 함수를 붙여넣습니다. 람다, 마지막 인수(A2) 없이만:

모든 것. 클릭 후 OK 생성된 함수는 이 통합 문서의 모든 시트에 있는 모든 셀에서 사용할 수 있습니다.

다른 책에서 사용
LAMBDA 및 동적 어레이
함수로 만든 사용자 정의 함수 람다 새로운 동적 배열 및 해당 기능에 대한 작업을 성공적으로 지원합니다(FILTER, 유니크, 학년) 2020년 Microsoft Excel에 추가되었습니다.
두 목록을 비교하고 두 목록에 없는 첫 번째 목록의 요소를 반환하는 새 사용자 정의 함수를 만들고 싶다고 가정해 봅시다. 인생의 일, 그렇지? 이전에는 이를 위해 다음 기능 중 하나를 사용했습니다. VPR (조회), 피벗 테이블 또는 파워 쿼리 쿼리. 이제 하나의 공식으로 할 수 있습니다.

영어 버전에서는 다음과 같습니다.
=LAMBDA(a;b;ФИЛЬТР(a;СЧЁТЕСЛИ(b;a)=0))(A1:A6;C1:C10)
여기서 기능 카운티 두 번째 목록에서 첫 번째 목록의 각 요소가 발생한 횟수를 계산한 다음 함수 FILTER 이러한 발생이 없는 항목만 선택합니다. 이 구조를 래핑하여 람다 예를 들어, 이름을 사용하여 명명된 범위를 생성합니다. 검색 분포 – 동적 배열 형태로 두 목록을 비교한 결과를 반환하는 편리한 함수를 얻습니다.

소스 데이터가 평범하지 않고 "스마트" 테이블인 경우에도 우리 함수는 문제 없이 대처할 것입니다.

또 다른 예는 텍스트를 XML로 변환하여 동적으로 분할한 다음 최근에 구문 분석한 FILTER.XML 함수를 사용하여 셀별로 구문 분석하는 것입니다. 이 복잡한 공식을 매번 수동으로 재현하지 않으려면 LAMBDA로 래핑하고 이를 기반으로 동적 범위를 생성하는 것이 더 쉬울 것입니다.

이 함수의 첫 번째 인수는 소스 텍스트가 있는 셀이고 두 번째 인수는 구분 문자이며 결과를 수평 동적 배열 형태로 반환합니다. 기능 코드는 다음과 같습니다.
=람다(t;d; 전치(FILTER.XML(“
예제 목록은 무궁무진합니다. 길고 복잡한 공식을 자주 입력해야 하는 상황에서 LAMBDA 함수를 사용하면 삶이 눈에 띄게 쉬워집니다.
재귀적인 문자 열거
이전의 모든 예는 LAMBDA 함수의 가장 분명한 한 가지 측면만을 보여주었습니다. 즉, 긴 공식을 래핑하고 입력을 단순화하기 위한 "래퍼"로 사용하는 것입니다. 사실, LAMBDA에는 거의 완전한 프로그래밍 언어로 바뀌는 훨씬 더 깊은 또 다른 측면이 있습니다.
사실은 LAMBDA 기능의 근본적으로 중요한 기능은 이를 구현하는 능력입니다. 재귀 – 계산의 논리, 계산 과정에서 함수가 스스로를 호출할 때. 습관상 소름 끼치게 들릴 수 있지만 프로그래밍에서 재귀는 흔한 일입니다. Visual Basic의 매크로에서도 구현이 가능하고, 이제 보시다시피 엑셀까지 왔습니다. 실용적인 예를 들어 이 기술을 이해하려고 노력합시다.
소스 텍스트에서 주어진 모든 문자를 제거하는 사용자 정의 함수를 생성한다고 가정합니다. 그러한 기능의 유용성은 증명할 필요가 없다고 생각합니다. 이 기능을 사용하면 흩어져 있는 입력 데이터를 지우는 것이 매우 편리할 것입니다. 그렇죠?
그러나 이전의 비재귀적 예와 비교할 때 두 가지 어려움이 우리를 기다리고 있습니다.
- 코드 작성을 시작하기 전에 함수의 이름을 생각해 내야 합니다. 왜냐하면 이 이름은 이미 함수 자체를 호출하는 데 사용되기 때문입니다.
- 이러한 재귀 함수를 셀에 입력하고 LAMBDA 뒤에 대괄호 안에 인수를 지정하여 디버깅하면(앞서 했던 것처럼) 작동하지 않습니다. 함수를 "처음부터" 즉시 생성해야 합니다. 이름 관리자 (이름 관리자).
함수를 CLEAN이라고 부르고 두 개의 인수를 갖기를 원합니다. 정리할 텍스트와 제외된 문자 목록을 텍스트 문자열로 지정합니다.

이전에 했던 것처럼 탭에서 생성해 보겠습니다. 공식 в 이름 관리자 명명된 범위, 이름을 CLEAR로 지정하고 필드에 입력 범위 다음 건설:
=LAMBDA(t;d;IF(d="";t;CLEAR(대체(t;LEFT(d);""));MID(d;2;255))))
여기서 변수 t는 지울 원본 텍스트이고 d는 삭제할 문자 목록입니다.
모두 다음과 같이 작동합니다.
반복 1
SUBSTITUTE(t;LEFT(d);””) 조각은 추측할 수 있듯이 소스 텍스트 t에서 삭제할 집합 d의 왼쪽 문자에서 첫 번째 문자를 빈 텍스트 문자열로 대체합니다. 즉, " ㅏ". 중간 결과로 다음을 얻습니다.
Vsh zkz n 125 루블.
반복 2
그런 다음 함수는 자신을 호출하고 입력(첫 번째 인수)으로 이전 단계에서 정리 후 남은 것을 수신하고 두 번째 인수는 첫 번째 문자가 아니라 두 번째 문자부터 시작하는 제외된 문자의 문자열입니다(예: "BVGDEEGZIKLMNOPRSTUFHTSCHSHSHCHHYYYYYA. ," 이니셜 "A" 없이 - 이것은 MID 기능에 의해 수행됩니다. 이전과 마찬가지로 이 함수는 나머지 문자(B)의 왼쪽에서 첫 번째 문자를 가져와서 주어진 텍스트(Zkz n 125 루블)에서 빈 문자열로 바꿉니다. 중간 결과를 얻습니다.
125루
반복 3
함수는 자신을 다시 호출하여 이전 반복(Bsh zkz n 125 ru.)에서 지워야 하는 텍스트의 나머지 부분을 첫 번째 인수로 수신하고, 두 번째 인수로 제외된 문자 집합을 다음으로 한 문자 더 잘립니다. 왼쪽, 즉 이니셜 "B"가 없는 "VGDEEGZIKLMNOPRSTUFHTSCHSHCHYYYYUYA.". 그런 다음 다시 이 세트의 왼쪽(B)에서 첫 번째 문자를 가져와 텍스트에서 제거합니다. 다음을 얻습니다.
sh zkz n 125 ru.
등등 – 나는 당신이 아이디어를 얻기를 바랍니다. 반복할 때마다 제거할 문자 목록이 왼쪽에서 잘리고 집합에서 다음 문자를 검색하여 공백으로 바꿉니다.
모든 문자가 다 떨어지면 루프를 종료해야 합니다. 이 역할은 함수에 의해 수행됩니다. IF (만약), 우리의 디자인이 포장되어 있습니다. 삭제할 문자가 남아 있지 않은 경우(d=""), 함수는 더 이상 자체를 호출하지 않고 지울 텍스트(변수 t)를 최종 형식으로 반환해야 합니다.
셀의 재귀 반복
마찬가지로, 주어진 범위에 있는 셀의 재귀적 열거를 구현할 수 있습니다. 라는 이름의 람다 함수를 생성한다고 가정해 보겠습니다. 교체 목록 주어진 참조 목록에 따라 소스 텍스트의 조각을 대량으로 대체합니다. 결과는 다음과 같아야 합니다.

저것들. 우리의 기능에서 교체 목록 세 가지 인수가 있습니다.
- 처리할 텍스트가 있는 셀(소스 주소)
- 조회에서 검색할 값이 있는 열의 첫 번째 셀
- 조회에서 대체 값이 있는 열의 첫 번째 셀
함수는 디렉토리에서 위에서 아래로 이동해야 하며 왼쪽 열의 모든 옵션을 순차적으로 교체해야 합니다. 찾다 오른쪽 열에서 해당 옵션으로 대용품. 다음 재귀 람다 함수를 사용하여 이를 구현할 수 있습니다.

각 반복에서 아래로 이동은 표준 Excel 기능으로 구현됩니다. 처분 (오프셋), 이 경우에는 원래 범위, 행 이동(1) 및 열 이동(0)의 세 가지 인수가 있습니다.
음, 디렉토리의 끝에 도달하자마자(n = ""), 재귀를 종료해야 합니다. 우리는 스스로 호출을 중단하고 소스 텍스트 변수 t의 모든 교체 후에 누적된 것을 표시합니다.
그게 다야. 까다로운 매크로나 파워 쿼리 쿼리가 없습니다. 전체 작업이 하나의 기능으로 해결됩니다.
- Excel의 새로운 동적 배열 함수 사용 방법: FILTER, SORT, UNIC
- SUBSTITUTE 함수로 텍스트 교체 및 정리
- VBA에서 매크로 및 사용자 정의 함수(UDF) 만들기